Statsig AI Evals Alternative: Self-Hosted Release Control for AI Changes
A useful Statsig AI Evals alternative is not always another all-in-one AI eval suite. For many AI product teams, the stronger alternative is a two-layer operating model: keep evaluation and grading where they fit your stack, then use FeatBit as the open-source, self-hosted release-control layer that decides who sees a candidate AI behavior, how fast it expands, which metrics decide the outcome, and how rollback works.
That distinction matters. FeatBit is not a native LLM judge and should not be evaluated as a drop-in replacement for every AI Evals screen. FeatBit is a release-decision platform. It helps teams turn AI eval evidence into controlled exposure, experiments, rollback, audit history, and cleanup.
The Short Answer
Choose a vendor AI eval suite when you want prompt management, datasets, graders, online eval dashboards, feature gates, experiments, and analytics bundled in one commercial workflow.
Consider FeatBit as a Statsig AI Evals alternative when your team already has, or wants to own, the evaluation layer and needs a portable release-control system around it:
- self-hosted feature flags for prompt, model, retrieval, or agent-policy routing;
- targeting rules and percentage rollout for staged AI exposure;
- experiment assignment and metric events for business outcomes;
- fast rollback to a baseline behavior without redeploying code;
- lifecycle ownership so temporary AI release controls do not become permanent clutter.
The practical question is not "Which product has the AI Evals label?" It is "Which system will own each release decision after an eval score changes?"
What Statsig AI Evals Publicly Bundles
Statsig's public AI Evals overview describes a broad workflow for LLM applications: prompts, offline evals, online evals, feature gates, experiments, analytics, and LLM-as-a-judge grading. Statsig's AI Evals landing page positions the product around offline and online evals, AI configs, prompt and model versioning, grading pipelines, dashboards, and experimentation.
That is useful category context. It also creates a buyer question: do you want the eval workflow, release control, analytics, and production experimentation inside one platform, or do you want a composable stack where the evaluation layer and the release-control layer remain separate?
There is also an availability caveat. The Statsig AI Evals documentation reviewed on June 8, 2026 says AI Evals are in beta and that Statsig is no longer accepting new beta customers. Treat availability, packaging, data handling, and support model as proof-of-concept questions, not assumptions.
When A FeatBit Alternative Model Makes Sense
FeatBit is strongest when the release-control layer needs to remain inspectable, portable, and close to your production systems.
| Situation | Why the FeatBit model fits |
|---|---|
| You already run offline evals in CI, notebooks, a model platform, or an internal service | The eval system can produce pass, repair, reject, or narrow decisions while FeatBit controls production exposure. |
| You cannot send prompts, outputs, or judge traces to every vendor tool | A self-hosted flag and experimentation layer can keep rollout state, targeting, and events inside your chosen boundary. |
| AI behavior changes require staged release | FeatBit can target internal users, beta accounts, risk tiers, regions, or a small percentage before broader exposure. |
| Business impact matters more than eval score alone | FeatBit experiments can connect served variation to custom outcome events and guardrails. |
| Rollback must be operational, not a new deployment | A runtime flag can return traffic to the baseline prompt, model route, retrieval profile, or tool policy quickly. |
| Temporary AI controls are multiplying | FeatBit's lifecycle model gives flags owners, evidence, review windows, and cleanup paths. |
This is a different promise from an AI eval dashboard. The eval dashboard explains the candidate. The release-control layer decides how the candidate reaches users.
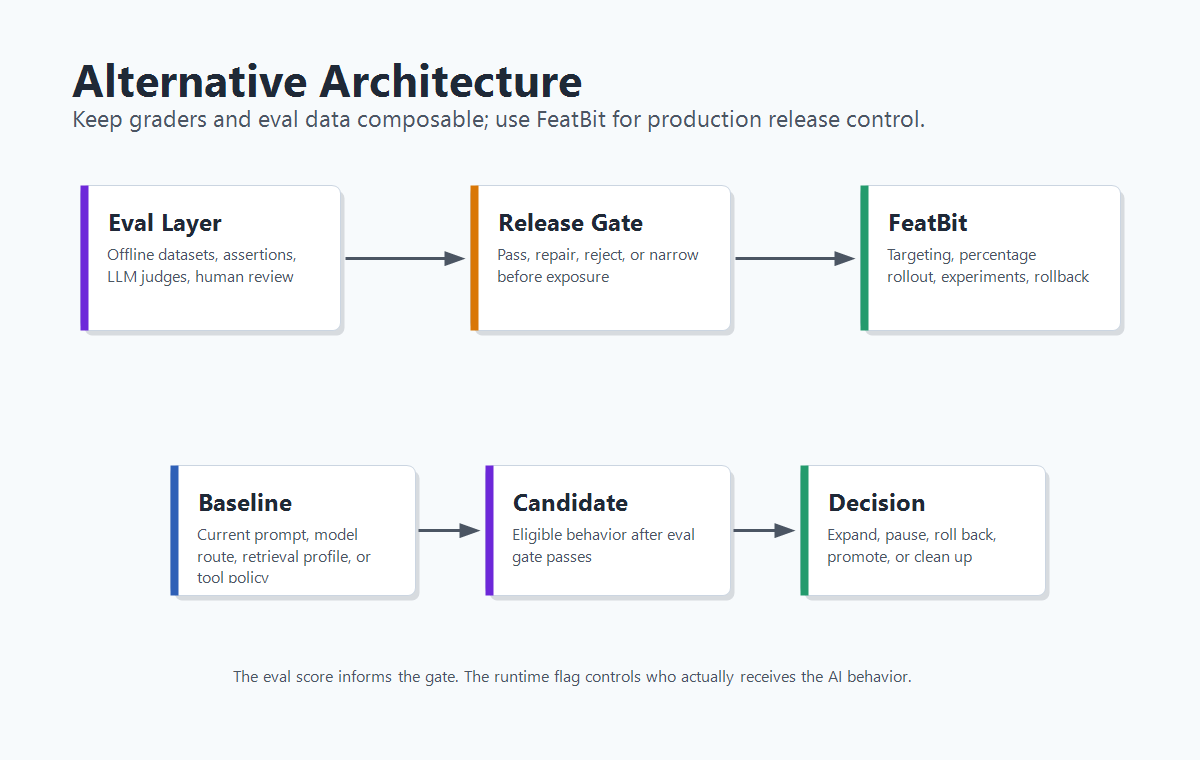
A Two-Layer Architecture For AI Evals
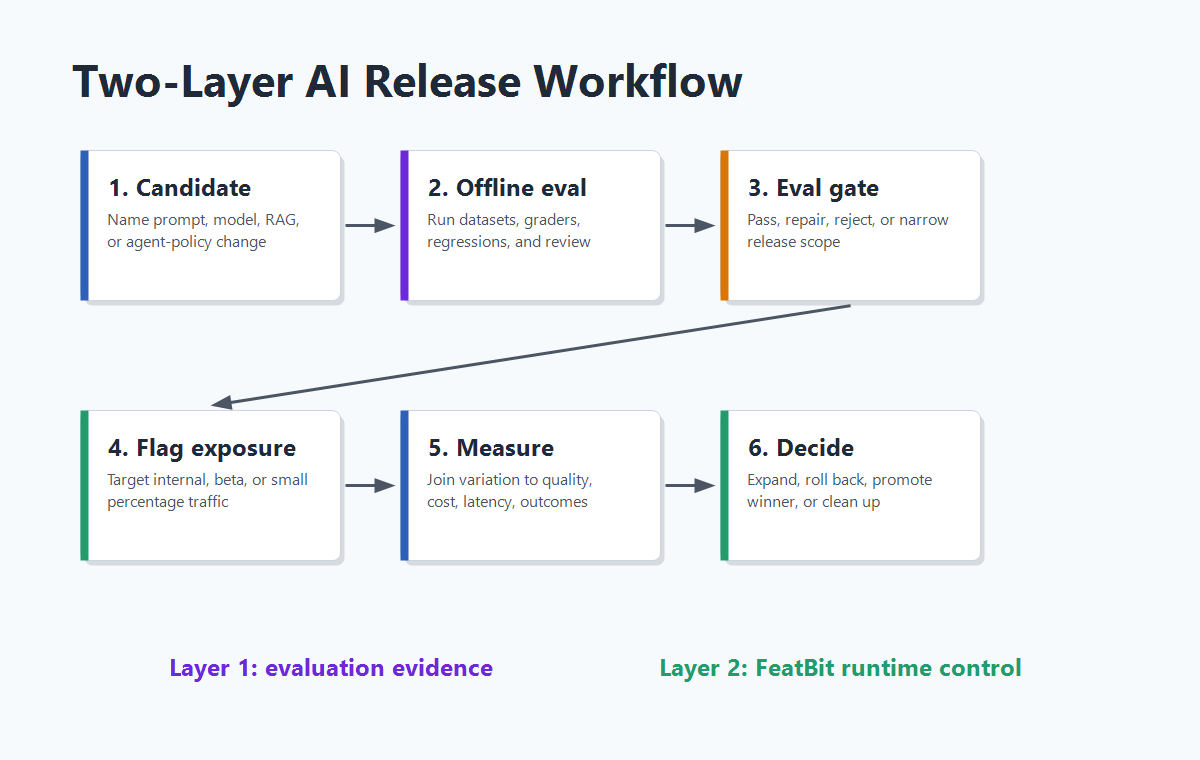
The architecture is simple:
- Define the AI behavior as a versioned release candidate.
- Run offline evals with your chosen datasets, graders, assertions, and human review.
- Convert the eval result into a release gate: pass, repair, reject, or narrow.
- Use FeatBit to keep the baseline and candidate behind a runtime flag.
- Target internal users, shadow paths, beta accounts, or a small live cohort.
- Track exposure only when the AI behavior actually runs.
- Join exposure to quality labels, latency, cost, fallback rate, and business outcomes.
- Expand, pause, roll back, or promote the candidate based on the decision contract.
- Clean up losing prompt, model, retrieval, or agent-policy branches after the decision.
This pattern keeps each tool honest. Evals judge behavior. Feature flags control exposure. Experiments decide outcome. Lifecycle rules prevent release debt.
What FeatBit Owns In The Workflow
FeatBit should own the runtime release decision, not the AI grader.
For example, a support team may evaluate support_prompt_v4 with an offline grader outside FeatBit. If the candidate passes protected account-security and billing cases, FeatBit can make the production route explicit:
const route = await flags.variation("support_assistant_route", user, "baseline");
if (route === "prompt_v4_model_b") {
return runSupportAssistant({
promptVersion: "v4",
modelRoute: "model_b",
});
}
return runSupportAssistant({
promptVersion: "v3",
modelRoute: "model_a",
});
The important part is not the code shape. The important part is the operating contract:
| Release concern | FeatBit responsibility |
|---|---|
| Eligibility | Only expose candidates that passed the agreed eval gate. |
| Targeting | Start with internal users, beta customers, low-risk workflows, or selected accounts. |
| Assignment | Keep assignment stable by user, account, conversation, workspace, or another unit that matches the product journey. |
| Measurement | Attach the served variation to outcome and guardrail events. |
| Rollback | Return traffic to the baseline without waiting for a new deployment. |
| Audit | Preserve who changed rollout state, when, and why. |
| Cleanup | Remove losing branches or mark long-lived operational controls deliberately. |
FeatBit implementation references include targeting rules, percentage rollouts, A/B testing with feature flags, and the Track Insights API.
Alternative Comparison Frame
Use this table to keep the comparison fair. It avoids the false claim that a release-control platform and an AI eval suite do the same job.
| Buyer question | Statsig AI Evals style of answer | FeatBit alternative model |
|---|---|---|
| Where do prompts and graders live? | In the vendor AI Evals workflow, based on public product positioning. | In your eval system, model platform, repository, or application service. |
| How are offline evals run? | Through the eval suite's datasets and grading pipeline. | Outside FeatBit, then passed into a release gate or workflow decision. |
| How is live exposure controlled? | Through feature gates, experiments, analytics, and AI configs in the Statsig platform. | Through FeatBit flags, targeting, rollout percentages, experiments, and rollback controls. |
| How is business impact measured? | In the bundled experimentation and analytics workflow. | Through FeatBit exposure and metric events, or exported events joined in your analytics stack. |
| How are data boundaries handled? | Verify directly with Statsig for your account, deployment, and contractual requirements. | Use FeatBit self-hosting when rollout state and event flow need to stay in your own environment. |
| What happens after the decision? | Verify lifecycle, prompt, config, and experiment cleanup behavior during the proof of concept. | Use FeatBit flag lifecycle rules to remove losing routes or preserve intentional operational controls. |
The best choice depends on where your team wants the center of gravity. If you want a productized AI eval suite, prove that path. If you want release control around a composable eval stack, prove the FeatBit path.
Proof-Of-Concept Checklist
Run one proof of concept around a real AI behavior, not a demo prompt.
ai_release_poc:
release_question: should_support_prompt_v4_expand_beyond_internal_users
baseline: support_prompt_v3_model_a
candidate: support_prompt_v4_model_b
assignment_unit: conversation_id
offline_eval_gate:
must_pass:
- billing_policy_regression
- account_security_regression
- required_citation_format
pass_action: enable_internal_flag_target
fail_action: repair_candidate
featbit_release_control:
flag_key: support_assistant_route
initial_target: internal_support_agents
canary_target: low_risk_support_threads
experiment_split: 50_50_after_canary
metrics:
primary: case_resolved_without_escalation
guardrails:
- complaint_rate
- human_correction_rate
- p95_latency
- cost_per_resolved_case
- fallback_rate
release_actions:
healthy: expand_or_experiment
guardrail_breach: rollback_to_baseline
final: promote_pause_or_cleanup
Ask every option to walk through the same path:
- Can the offline eval result become a written release gate?
- Can production exposure start with a narrow audience?
- Can assignment stay stable for the real journey, such as a conversation or account?
- Can the served variation be joined to quality, cost, latency, and business outcome events?
- Can the operator roll back to baseline without a deployment?
- Can the team remove or archive temporary controls after the decision?
If a tool cannot answer those questions, it may still be a useful eval product, but it is not the whole release system.
When Statsig May Still Be The Better Fit
Statsig may be the better first choice when your team wants a managed product workflow that brings AI configs, prompt and model versioning, offline evals, online evals, experiments, analytics, and dashboards together. That can reduce integration work if the product shape, availability, data requirements, SDK support, and procurement model fit your organization.
Keep the comparison specific. FeatBit's advantage is not that it replaces every AI Evals feature. FeatBit's advantage is that it can be the open-source, self-hosted release-control layer around whichever eval evidence your team trusts.
Common Mistakes When Looking For An Alternative
Looking for a label match instead of an operating model. A product named "AI Evals" may include release capabilities. A feature flag platform may not grade outputs. Compare the decisions each system can own.
Treating offline eval pass as launch approval. Offline evals can block known failures. They cannot prove live user preference, production traffic mix, segment safety, or business impact.
Skipping assignment design. A random request-level split can break multi-turn AI experiences. Choose user, account, conversation, workspace, or workflow assignment deliberately.
Recording exposure too early. A page view is not an AI exposure if the candidate prompt, model route, retrieval profile, or agent policy did not affect the response.
Forgetting rollback until the incident. The baseline path must remain available before traffic expands.
Leaving temporary AI controls forever. Prompt routes, model aliases, retrieval settings, grader versions, and experiment flags need cleanup once the decision is made.
Bottom Line
A Statsig AI Evals alternative can mean two different things. If you need an all-in-one managed eval suite, evaluate products that own prompts, graders, dashboards, online evals, experiments, and analytics together.
If you need a self-hosted release-control layer around AI eval evidence, FeatBit is the alternative operating model: use your evals to judge the candidate, use FeatBit to control exposure, use experiments and metric events to decide business impact, and keep rollback and cleanup available throughout the AI release.
Source Notes
- Statsig product context: Statsig's AI Evals overview describes prompts, offline evals, online evals, feature gates, experiments, analytics, LLM-as-a-judge grading, and the beta availability caveat reviewed on June 8, 2026.
- Statsig landing page context: Statsig's AI Evals landing page describes offline and online evals, AI configs, prompt and model versioning, grading pipelines, dashboards, and experimentation.
- Feature gate and experiment context: Statsig's feature gates versus experiments guide supports the distinction between gradual rollout and variant comparison.
- Vendor-neutral flag context: the OpenFeature flag evaluation specification provides vendor-neutral language for typed flag evaluation and default behavior.
- FeatBit release-control context: AI experimentation, safe AI deployment, feature flag lifecycle management, and self-hosted feature flags support the FeatBit angle in this article.
- FeatBit implementation context: targeting rules, percentage rollouts, A/B testing with feature flags, and the Track Insights API are practical next steps for implementation.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it frames the page as a Statsig AI Evals alternative guide with FeatBit's release-control angle. - Use
alternative-architecture.pngnear the opening because it shows eval tools feeding FeatBit release control. - Use
two-layer-workflow.pngin the architecture section because it visualizes the handoff from eval evidence to rollout decision.