The 2026 Productivity Paradox of AI Coding: Why Faster PRs Need a Safer Release System
AI coding agents are no longer a side experiment. In 2026, engineering organizations are running them at scale — and the numbers are starting to tell a more complicated story than the productivity demos.
Recent industry telemetry, practitioner surveys, large-enterprise studies, and academic research all point in the same direction: AI-assisted coding does raise throughput, but it also raises bugs, review time, incidents, churn, and long-term maintenance load. The output increases. The reliability tax increases with it.
This article walks through what the 2026 evidence actually says about AI coding's enterprise impact, why these failures keep happening, and what kinds of engineering controls — including feature flags, but not only feature flags — turn raw AI speed into safe delivery.
Download the full evidence base behind this article, including the studies and release-control argument summarized below.
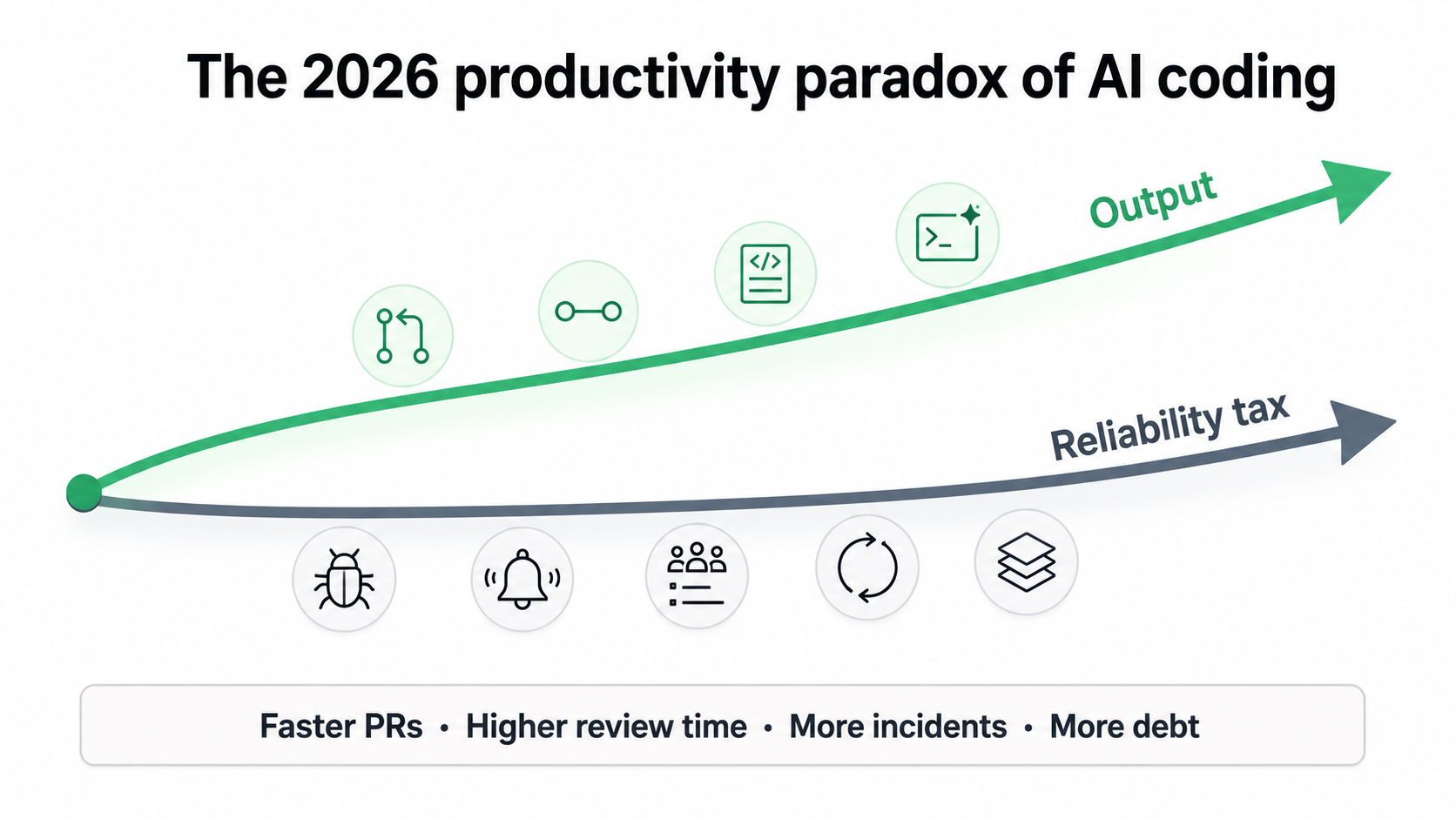
The Productivity Paradox
Multiple 2026 sources — vendor-neutral telemetry, developer surveys, practitioner research, and PR-quality and deployment studies — describe the same shape. Productivity goes up. So does the cost of fixing what AI ships.
Faros AI: more throughput, more everything else
Faros AI's Acceleration Whiplash telemetry — drawn from 22,000 developers across 4,000 teams — reports that AI-heavy organizations are shipping more, but the operational picture changes alongside it:
| Signal in AI-heavy orgs | Change vs. baseline |
|---|---|
| PR size | +51% |
| Bugs per PR | +28% |
| Median review time | 5× |
| Incidents per PR | 3× |
| Code churn | 10× |
Throughput metrics like epics completed and task throughput do move up. But every signal downstream of the keyboard — review, defects, incidents, churn — moves up too.
SonarSource: developers feel the speed, and don't trust the code
SonarSource's 2026 State of Code developer survey (n = 1,149) captures the human side of the same trade-off:
| What developers report | Share |
|---|---|
| Average self-reported productivity gain | 35% |
| Do not fully trust AI-generated code | 96% |
| Spend time reviewing, testing, or correcting it | 95% |
| Say reviewing AI-generated code takes more effort than a coworker's code | 38% |
| Always check AI-assisted code before committing | 48% |
That last number matters. Almost half of AI-assisted commits enter the repository without a verification step the developer themselves would consider mandatory.
The Pragmatic Engineer: the burden is unevenly distributed
The Pragmatic Engineer's 2026 AI tooling survey, based on 900+ reader responses, adds a practitioner lens to the telemetry. The pattern is not just "AI helps" or "AI hurts." The effects depend heavily on the role, taste, and operating model of the engineer using it.
| Practitioner signal | What it suggests |
|---|---|
| AI costs are a recurring concern | Tooling spend is becoming an organizational constraint, not just a developer preference |
| About 30% of respondents report hitting usage limits | AI-assisted work can be interrupted by budget, quota, and model-access ceilings |
| Builders report more review and debugging pressure | The quality burden often shifts toward engineers who care most about architecture and maintainability |
| Shippers report faster delivery | AI accelerates people who already optimize for getting changes into production |
| Less experienced or less quality-focused users can generate more low-quality output | AI amplifies existing engineering habits rather than replacing engineering judgment |
That makes the paradox sharper. AI tooling can raise the apparent output of a team while moving more verification, cleanup, and architectural judgment onto a smaller set of senior engineers. If that burden is invisible in planning, the organization sees faster shipping before it sees the downstream queue forming.
CodeRabbit and Harness: the cost reaches production
The CodeRabbit study summarized by Stack Overflow looked at 470 open-access repositories and found AI-authored PRs carried:
| Issue type in AI-authored PRs | Multiplier vs. human PRs |
|---|---|
| Overall issues | ~1.7× |
| Logic and correctness errors | +75% |
| Security issues | 1.5–2× |
| Readability issues | 3× |
Harness's 2026 State of DevOps Modernization report, based on 700 engineering practitioners and managers at large enterprises, ties this back to production:
| Production signal | Value |
|---|---|
| Say AI-generated code leads to deployment problems at least half the time | 69% |
| Deployments from very-frequent AI users ending in rollback, hotfix, or customer incident | 22% |
| Median MTTR | 7.6 hours |
| Downstream effects | More vulnerabilities, more compliance issues, more performance problems, more manual cleanup |
The gains are real. So is the bill. The honest reading is not "AI coding is bad." Anthropic's 2026 Agentic Coding Trends report describes CRED doubling execution speed and TELUS shipping engineering code 30% faster while saving 500,000+ hours. The honest reading is that local coding speed and system-level delivery safety are different metrics, and they need to be managed separately.

Why It Happens
When people describe AI coding failures, "hallucination" is the word that gets used. The 2026 evidence suggests that is rarely the main story. The dominant failure mode is plausible code that survives ordinary gates and fails inside the system.
The bugs are in the integration layer, not the algorithm
Engineering Pitfalls in AI Coding Tools (Claude Code, Codex CLI, Gemini CLI; 3,864 real-world issues from public trackers) breaks down where the failures actually live:
| Where AI coding bugs concentrate | Share |
|---|---|
| Functional bugs | 67% |
| API, integration, or configuration errors | 37.3% |
| Highest-density layers | Tool/API orchestration and command execution |
This matches what teams report informally: the agent writes code that "looks fine" but uses the wrong utility, the wrong version, the wrong config key, or the wrong tool for the runtime.
Speed gains are transient. Complexity is not.
The arXiv study Speed at the Cost of Quality used a difference-in-differences design against 1,380 matched control repositories to measure Cursor adoption. The pattern is striking:
| After Cursor adoption | Effect |
|---|---|
| Lines-added growth in month 1 | 3–5× |
| Velocity gain in subsequent months | Dissipates |
| Static-analysis warnings | +30% |
| Code complexity | +41% |
The speed advantage is front-loaded; the complexity it leaves behind is permanent.
AI-introduced issues survive
Debt Behind the AI Boom analyzed 302,532 AI-authored commits from 6,299 GitHub repositories across five assistants:
| AI-authored commit finding | Value |
|---|---|
| Commits from every studied assistant that introduced ≥1 issue | >15% |
| Per-tool issue introduction rate (range) | 17.4% (GitHub Copilot) – 29.1% (Gemini) |
| Code smells | Net fix (more fixed than introduced) |
| Correctness and security issues | Net introduction (more added than fixed) |
| AI-introduced issues still surviving at repo head | 22.7% |
Plausible-looking code does not get caught and reverted. It accumulates.
Even mature gates miss it
Anthropic's April 23, 2026 Claude Code postmortem is the most public example. A combination of lower default reasoning effort, a context-clearing bug, and a verbosity-limiting system prompt produced a real coding-quality regression — roughly a 3% eval drop. It passed human review, unit tests, end-to-end tests, and dogfooding before users felt it.
If Anthropic's own pipeline could let that through, no team should assume that "we have CI" is the same as "we will catch it."
The four context losses behind all of this
Underneath those measurements is a structural pattern. AI-generated PRs lose context in four recognizable ways:
Requirement memory loss. The agent sees the current ticket but not the previous product decision, customer exception, security constraint, or rollout lesson that should shape the implementation.
Codebase context loss. The agent sees nearby files but not the deeper architecture pattern. It adds a new utility instead of reusing an existing one. More Code, Less Reuse documents exactly this — AI-generated PRs show more semantic redundancy than human PRs, while reviewers are not harsher and are often more neutral or positive. The duplication enters silently.
Review context loss. The reviewer sees the diff but not the agent's path: what it tried, what it rejected, what it assumed, where it was uncertain.
Organizational memory loss. The PR merges, the chat disappears, and the next engineer or agent has to rediscover why the code looks the way it does.
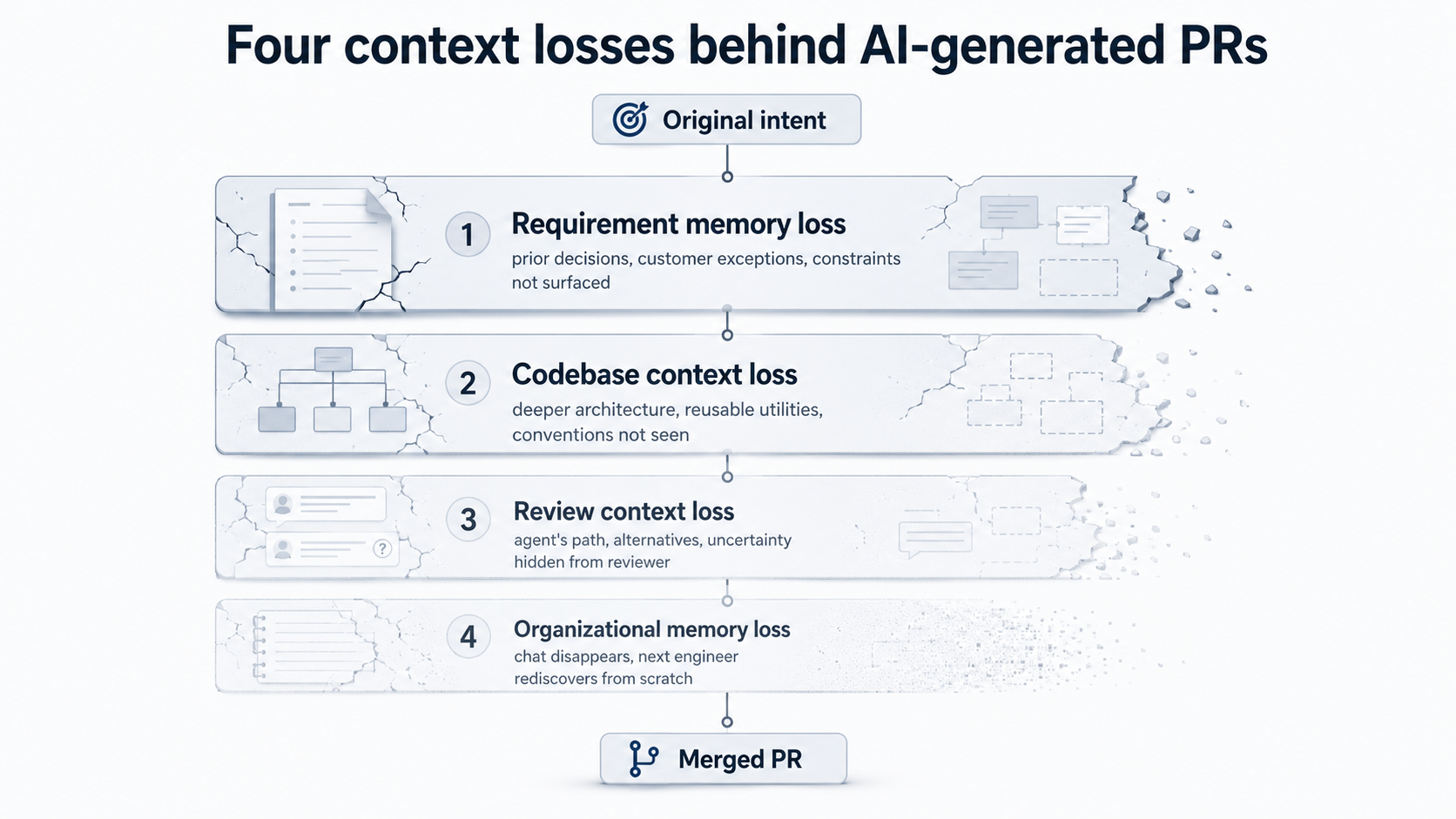
These four losses explain why the same problems keep showing up across the Faros, SonarSource, CodeRabbit, Harness, Cursor, and Anthropic findings. The model is improving. The context surrounding the model — what reaches it, what survives review, what is remembered after merge — is mostly unchanged.
What Doesn't Work
Three common reactions to this evidence look reasonable and do not actually solve it.
"Just review harder." Faros already shows median review time at 5× under heavy AI adoption. GitHub's 2026 guidance on reviewing agent PRs explicitly warns that agent-generated PR volume is saturating reviewer bandwidth. The Pragmatic Engineer's survey adds the human version of the same problem: quality-focused builders are often the people absorbing extra AI-generated review and debugging work. Asking reviewers to do more, slower, on every PR is not a recoverable strategy.
"Just test harder." Anthropic's randomized coding-skills study (52 mostly junior engineers) showed AI users scored 17% lower on mastery, with the biggest gap on debugging questions. Heavier delegation correlated with worse scores. The teams writing the tests are losing some of the conceptual ground that makes tests sharp.
"Just use less AI." The throughput, satisfaction, and "otherwise not worth it" work gains in Anthropic's and SonarSource's reports are real, and the METR developer-productivity update notes that newer agentic tools likely do deliver speed gains even if measurement is now selection-biased because developers refuse to work without them. Pulling AI back is neither realistic nor a clear win.
The 2026 evidence points to a different framing. The bugs, incidents, and debt are not failures of code generation. They are failures of delivery control: what context the agent had before it acted, what reviewers can verify, what production exposure looks like, and what happens when something goes wrong after merge.
Three Things That Actually Help
The methods most supported by recent evidence form a control loop with three stages: before the agent acts, before users see the change, and after the change is live.
1. Before the agent acts: repository rules and review memory
The first lever is what the agent reads before writing anything. GitHub's context engineering guidance makes the point directly: better output comes from durable context — repository rules, examples, constraints, custom instructions — not just better prompts.
Concretely, this means files like AGENTS.md or .cursorrules that encode:
- Which patterns and utilities already exist and should be reused.
- How feature flags are registered, named, and evaluated.
- Where business rules live and which ones are not negotiable.
- Test, security, and rollout expectations.
The second lever is review memory — durable context attached to every AI-assisted PR. Not a longer description; a structured artifact that captures intent, assumptions, risk, verification, and rollout plan, so reviewers and future maintainers (human or agent) can recover the reasoning without rereading a chat log.
This compresses review effort onto the places where human judgment matters most, which is the only response to Faros's 5× review-time number that does not require hiring more reviewers.
Products like tracewoven are starting to form around this need, treating PRs and AI conversations as reusable engineering memory rather than disposable artifacts.

A lightweight template teams can adapt:
**Coding Agent Context**
- Agent/tool used:
- What the agent helped with:
- Files or modules touched:
- Existing patterns/utilities checked:
**Intent**
- User/business problem:
- Acceptance criteria:
- Non-goals:
**Assumptions and Memory**
- Requirements or prior decisions used:
- Product/customer constraints:
- Architecture constraints:
- Uncertain assumptions:
**Risk**
- Critical path reviewers should trace:
- Security/privacy concerns:
- Performance concerns:
- Failure modes:
**Verification**
- Tests added:
- Manual checks:
- Static analysis/security checks:
- Known gaps:
**Release Control**
- Feature flag key:
- Initial audience:
- Rollout stages:
- Metrics/logs/alerts to watch:
- Rollback plan:
- Cleanup condition and expected removal date:
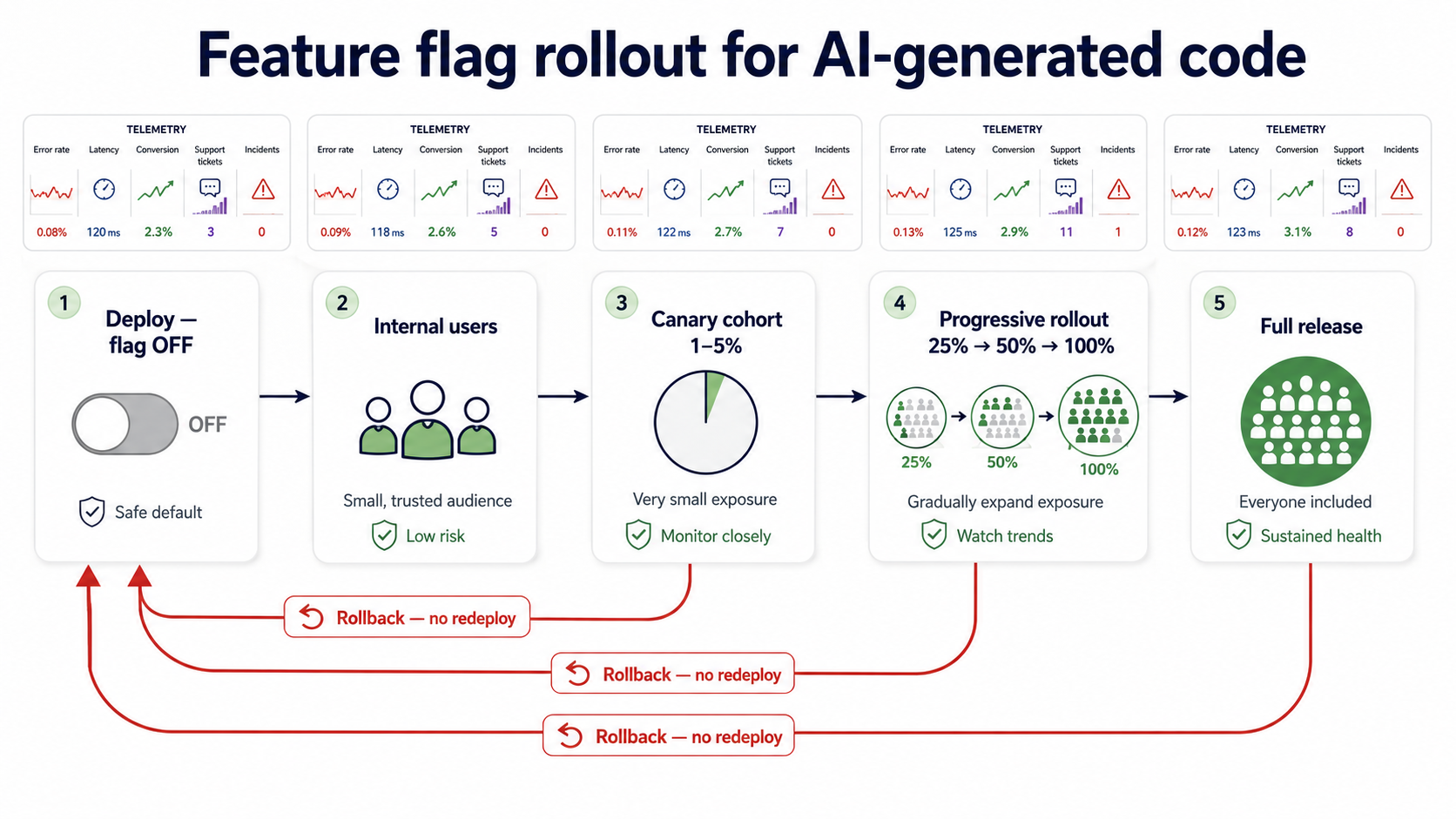
2. Before users see the change: feature flags and progressive rollout
Feature flags do not prevent AI from writing wrong code. They make wrong code less expensive to discover.
That distinction matters because the 2026 data shows wrong code will reach production. Harness's report puts the rollback/hotfix/customer-impacting incident rate at 22% of deployments for very-frequent AI users, with 7.6-hour MTTR. The right question is not whether to expect production-grade defects, but how to shrink the blast radius when they happen.
Feature flags give the team an explicit control surface:
- Deploy with the feature off.
- Enable for internal users first.
- Roll out to a small customer cohort.
- Watch SLOs, error rates, latency, conversion, support tickets.
- Disable the flag — without redeploying — if behavior is bad.
- Continue rollout only when evidence is healthy.
This is the same separation FeatBit has long emphasized between canary deployment and canary release: deployment moves code into an environment, release exposes behavior to users. AI-generated code makes the separation more valuable because code now arrives faster than the organization can safely absorb it.
The pattern is not theoretical. Harness's published case studies show it working at scale: Swedbank (50+ teams) running more frequent releases with feature flags and canary-style real-time testing; Vida Health moving mobile release cadence from monthly to weekly with phased rollouts and instant rollback; Experian (3,000 engineers and PMs) going from 2 big-bang releases per month to 100 risk-controlled deployments per month behind flags.
The same Harness research also identifies the gap: in its 2026 State of AI in Software Engineering survey, only 6% of respondents say their CD is fully automated. The AI coding wave is hitting release systems that are not ready for it.
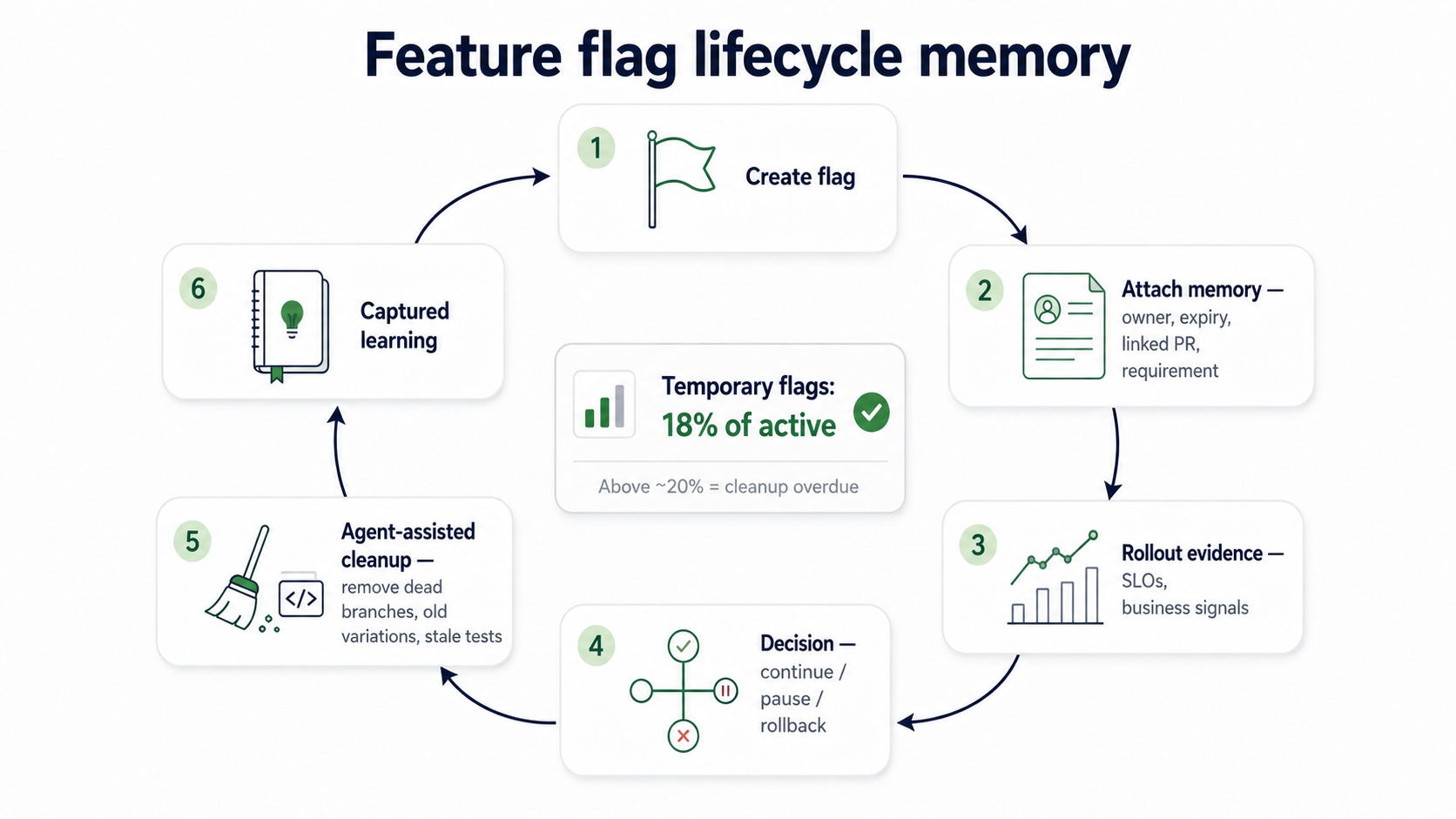
3. After the change is live: lifecycle memory and rollback discipline
The third lever is what happens after merge. Without it, the safety system becomes its own form of debt.
Debt Behind the AI Boom already shows that 22.7% of AI-introduced issues persist at repository head. Feature flags added defensively by agents — and never cleaned up — are one of the most visible expressions of that pattern. Every undecided rollout becomes a permanent branch in the codebase.
The mitigation is treating each flag as a memory artifact, not just a kill switch. A live flag should carry:
- An owner.
- The linked PR, requirement, and review memory.
- The rollout stage and audience.
- The decision criteria for continue, pause, or rollback.
- An expiry date or cleanup condition.
This is where agent skills become a multiplier instead of a liability. The cleanup work humans usually postpone — search all references, identify dead branches, remove old variations, update tests, update documentation, confirm no stale flag key remains — is mechanical, well-scoped, and exactly the kind of task an agent operating inside repository rules can do reliably.
This website's AGENTS.md is a simple example: it tells coding agents that all FeatBit feature flag integration lives in a typed registry, a server-side evaluation helper, and a user-context helper, and that client components must receive evaluated values as props rather than calling the SDK directly. Those rules make flag usage consistent for humans, but they are especially valuable for agents because agents can apply them mechanically every time.
A practical smell: when temporary release and experiment flags exceed roughly 20% of active production flags, cleanup is overdue. (Permanent operational controls — kill switches, entitlement gates, region controls, customer-specific configuration — are different and stay.)
A stale flag is rarely a code problem. It is a memory problem: the team forgot why it existed, who owned it, what evidence was needed to remove it, or what depended on it. The same memory layer that makes review tractable also makes cleanup tractable.
A Control Loop for AI-Generated PRs
Put together, the three stages form a loop:
flowchart LR
A[Human intent and acceptance criteria] --> B[Coding agent + repo rules]
B --> C[Review memory in PR]
C --> D[Human critical-path review]
D --> E[Merge behind feature flag OFF]
E --> F[Internal rollout]
F --> G[Canary cohort]
G --> H[Observe SLOs, errors, business signals]
H --> I{Healthy?}
I -- Yes --> J[Progressive rollout]
I -- No --> K[Disable flag or rollback]
J --> L[Capture learning + clean up flag]
K --> L
L --> A
The loop is what turns AI-assisted coding from a one-way code generator into a feedback system. Every stage produces evidence the next stage can act on, and every release leaves engineering memory the next agent and next reviewer can use.
Safe Efficiency Is the Goal
AI-assisted coding is useful because the productivity gains are real. They are also expensive when delivery controls do not keep up. The 2026 evidence is clear that the second half of that sentence is where most teams currently are.
Lines of code, PR count, and time-to-first-draft are easy to measure and not enough. The better question is whether the organization can absorb faster change safely — and what it will look like six months after a defective AI-generated change merges, when 22.7% of those issues are still living at the repository head.
Repository rules and review memory keep AI-generated PRs understandable. Feature flags and progressive rollout keep releases reversible. Lifecycle memory and agent-assisted cleanup keep the control system itself from turning into the next form of debt.
That is the practical path forward: not less AI, and not blind autonomy. More throughput, with memory. Faster delivery, with rollback. More agent help, with a release system that can say continue, pause, or turn it off.
In the AI era, the safest teams will not be the teams that avoid coding agents. They will be the teams that make agent-generated change reviewable before merge, controllable after merge, and learnable after release.