Should You Add A/B Testing to Your Homepage H1? A Real FeatBit Experiment
FeatBit started as feature flag infrastructure. Over the past several months we built a new experimentation platform on top of that foundation: FeatBit Experimentation.
The reason is simple: A/B testing is easy to start and surprisingly easy to get wrong, especially if you are not an experienced data scientist or growth product manager. A team can launch a test with an unclear hypothesis, the wrong success metric, polluted traffic, or an analysis method that does not match the business question. By the time the data arrives, the damage is already baked into the experiment design.
FeatBit Agentic Experimentation uses the coding-agent pattern to make that process more accessible. We integrated established A/B testing playbooks, research papers, classic best practices, and Bayesian analysis code into an agent-guided workflow. The goal is not to turn every PM or engineer into a statistician. It is to help ordinary product and engineering teams run professional, business-aligned experiments without skipping the parts that make the result trustworthy.
When we were ready to talk about it publicly, I faced a real question I could not answer by intuition alone: should we change our homepage H1 to mention AB testing, or would that hurt more than it helps? I decided to run an experiment to find out — using FeatBit itself.
The Dilemma
Our homepage H1 has always focused on feature flag cost efficiency — a message that resonates with engineering teams looking for a self-hosted alternative to LaunchDarkly.
The control headline is:
Cut Feature Flag Infra Costs by Up to 20×
The treatment headline is:
Cut Feature Flag and AB Testing Costs by Up to 20×
Adding AB testing could go two ways: attract teams that want both flags and experiments in one tool, or confuse developers who came for a focused feature flag service and bounce.
My instinct was that adding AB testing would make the message stronger. But most of our existing customers had never asked for AB testing explicitly, so I worried the new wording might change how they understood FeatBit: from a focused feature flag platform into something that sounded less specialized. The only clean way to resolve that tension was a randomized experiment with a single changed variable.
What the AI Helped Me Get Right
My first hypothesis was: "Mentioning AB testing in the H1 will attract a broader audience and increase trial signups."
The AI flagged two problems immediately. First, "broader audience" is not measurable — the experiment would not capture audience composition shifts. Second, "trial signups" was imprecise: does clicking the CTA count, or completing registration, or the first flag evaluation? Each definition produces a different funnel.
I settled on hero CTA engagement as the primary metric — the proportion of visitors who click any CTA in the hero area, including Open SaaS, Start with Docs, or the deployment icons. The headline only changes the hero, so this metric is close to the thing the headline can actually influence. It is also more stable than looking only at Open SaaS clicks, because it has more events and less variance.
I added two guardrails:
- Bounce rate — the proportion of visitors who leave without clicking anything. Lower is better.
- Open SaaS click rate — the proportion of visitors who click the core Open SaaS CTA. This catches cannibalization: hero engagement should not improve by pulling attention away from the most important conversion click.
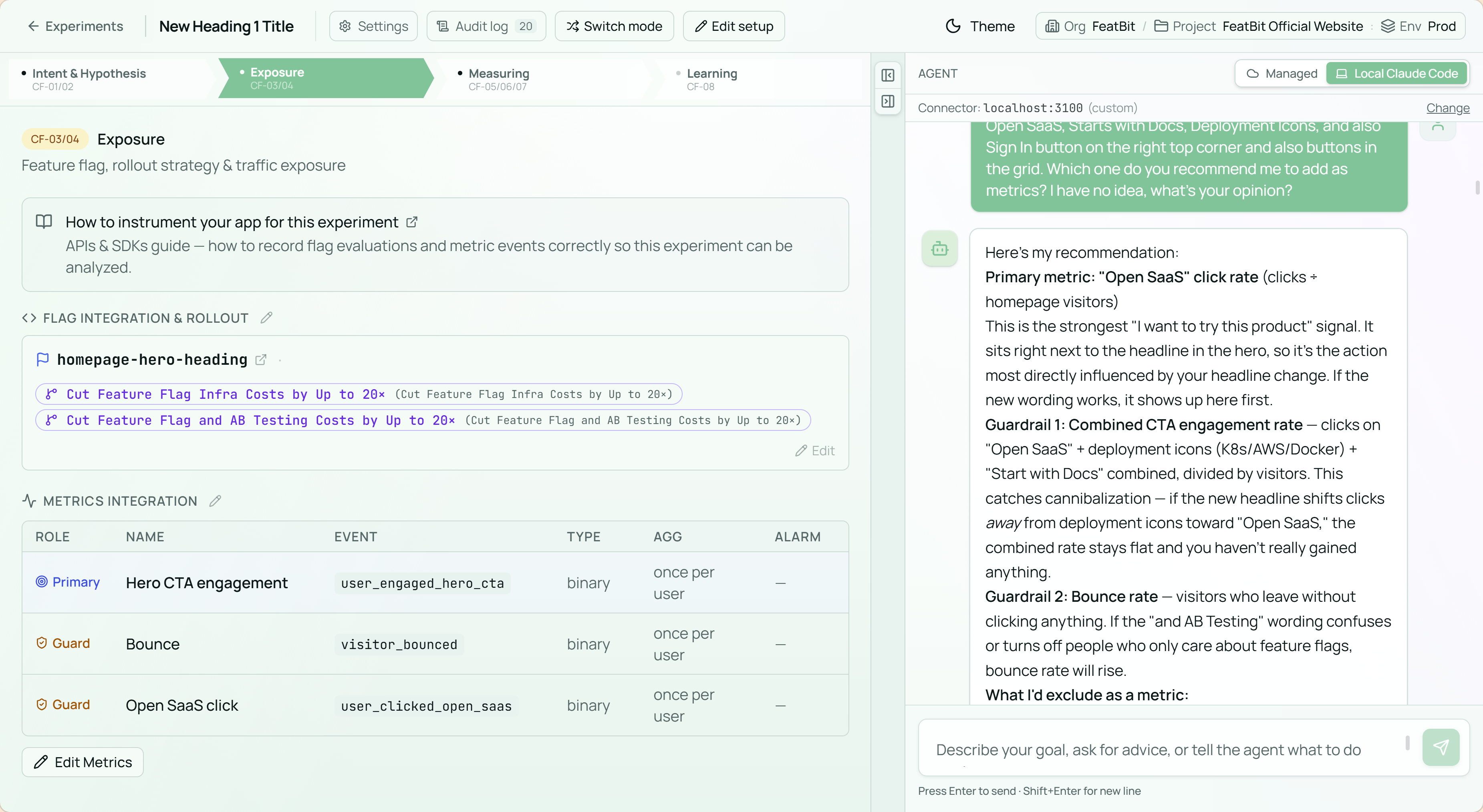
For traffic split, I initially wanted 80/20 to limit risk. The AI pushed back: asymmetric splits need longer run time, and longer run time means more exposure to external factors that corrupt results. We landed on a 50/50 split starting April 28. The analysis uses a Bayesian method with a flat prior and a minimum sample target of 200 visitors per variant.
The key insight: experiment quality is fixed at the moment you start, not at the moment you analyze. You cannot change the primary metric mid-experiment. Getting the design right before the first user is assigned is the only leverage you have.
The Technical Setup
The H1 is controlled by a feature flag in src/lib/featbit/flags.ts:
homepageHeroHeading: {
key: "homepage-hero-heading",
type: "string",
fallback: "Cut Feature Flag and AB Testing Costs by Up to 20×",
},
The flag is evaluated server-side on every request — no layout shift, no client-side flicker of the wrong headline. The anonymous user ID from the fb_anon_uid cookie is the bucketing seed, so returning visitors always see the same variant.
When a visitor clicks a hero CTA, the browser posts to /api/track. The route handler reads the cookie and records user_engaged_hero_cta, linking the event to the variant that visitor saw.
A Question That Came Up Mid-Experiment
FeatBit has a SaaS tier. When an enterprise customer invites team members to their organization, those members land on the homepage through a direct invite link. For them, clicking "Open SaaS" is the only reason they are there — their click probability is high regardless of the headline.
These users inflate the CTA click rate in both variants equally. The dilution is symmetric, so it does not bias the result directionally. But it reduces sensitivity: a real headline effect looks smaller than it is because a portion of clicks carry no signal about the headline at all.
There is also a harder version of the problem. If invite emails go out in batches, invited members might arrive unevenly across the experiment window. A spike in one week could shift the per-week conversion rate in ways that look like a variant effect. The AI called this population contamination.
Two fixes:
- Exclusion rule — add a targeting rule in the FeatBit portal that routes invited members to a fixed value before the bucketing rule fires. Their clicks never enter the experiment.
- Post-hoc segmentation — track invited-member visits separately and re-run the analysis without them. If the result is stable, the headline effect is real.
I added the second approach as a post-analysis plan. It is a good example of a concern that only surfaces once the experiment is actually running — and exactly where AI guidance is useful: turning a vague worry into a concrete, actionable decision.
Where Things Stand
The experiment is still in the measuring stage, and the current verdict is inconclusive.
The latest run has 111 visitors in control and 127 in treatment, which is only about 56-64% of the planned 200 visitors per variant. The posterior risk for the treatment has not converged yet, so the experiment has not passed the evidence gate for a formal continue, pause, or rollback decision.
The primary metric is worth watching. Hero CTA engagement is now 20 of 111 for control, or 18.0%, versus 19 of 127 for treatment, or 15.0%. That is a -17.0% relative delta for the treatment. Earlier analyses around 55 and 68 visitors showed treatment with about a 79% chance of winning; after the sample roughly doubled, that probability fell to 24.3%.
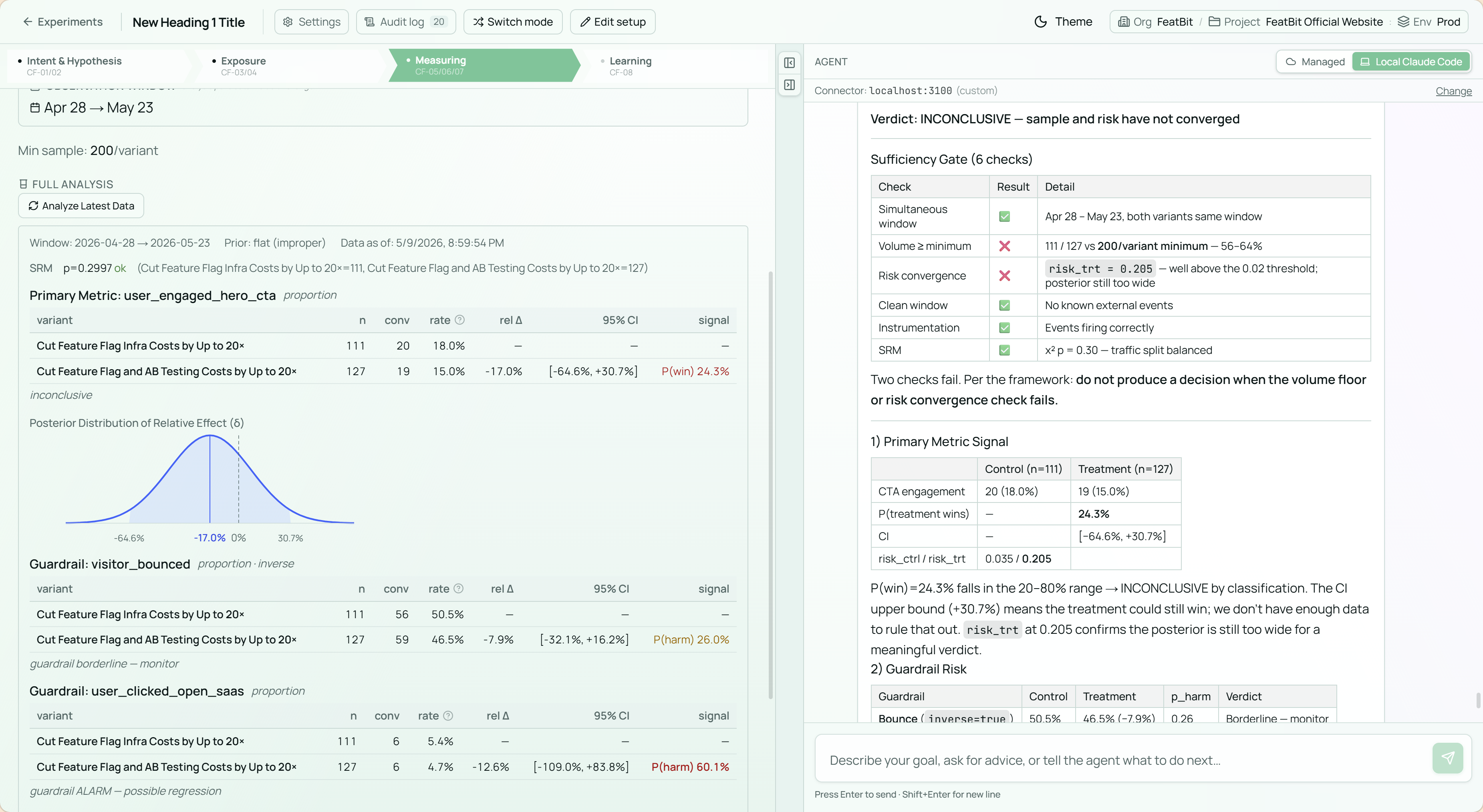
That reversal matters, but it is not yet decisive. It suggests the early positive signal may have been small-sample noise. At the same time, the credible interval is still wide, from -64.6% to +30.7%, which means we cannot rule out the treatment being better. The SRM check is healthy, so the traffic split itself does not look suspicious.
The guardrails also point to monitoring rather than action. Bounce is configured as an inverse metric, because lower is better, and it is slightly better for treatment: 50.5% in control versus 46.5% in treatment. Open SaaS clicks are slightly lower in treatment, 5.4% versus 4.7%, and the analysis marks it as an alarm. But that is still only 6 clicks in each variant, so I treat it as directionally worrying rather than confirmed harm.
This is exactly why the experiment was worth running. My intuition was that adding AB testing would strengthen the message. The data did not support that intuition, at least not with this wording and this audience.
The next step is to keep collecting until the experiment reaches the 200-per-variant minimum, likely around mid-May at the current traffic rate. If treatment wins with high confidence, we continue. If it stays in the 20-80% range after the full window, we close it as inconclusive. If the primary metric or the Open SaaS guardrail crosses a real harm threshold, we treat it as a rollback candidate.
If you are thinking about running an experiment but are not sure where to start, FeatBit Experimentation is built for exactly that situation. You do not need to be a statistician. You need a clear question, a measurable outcome, and a tool that stops you from making the most common mistakes before it is too late to fix them.
FeatBit is that tool. And we use it on ourselves.